

A conference called “The promises and pitfalls of preregistration” was hosted by the Royal Society in London from 4th-5th March 2024. Here, I discuss the presentations by Chris Donkin and Stephan Lewandowsky, both of which consider some of the potential “pitfalls” of preregistration.

Chris Donkin
Here’s the abstract for Chris’ presentation:

And you can find a recording of his presentation here…
For me, Chris’ key point was that p-hacking and preregistration both depend on arbitrary reasoning. P-hacking refers to the size of a p value (e.g., higher or lower than .050) in order to determine whether to report a test. Preregistration refers to the timing of the decision to report the p value (i.e., before or after looking at the p value) in order to determine the evidential status of that result (i.e., confirmatory or exploratory). Certainly, preregistered tests will report p values regardless of their size (i.e., significant or nonsignificant). However, they’ll also report p values regardless of whether the theoretical, methodological, and analytical reasons for conducting the associated tests are good or bad. Hence, both preregistration and p-hacking use arbitrary criteria (p values and timing) to decide what to report! As Chris explained…
Replacing one arbitrary reason for an analysis (i.e., the size of a p-value) with another (i.e., I said it beforehand) doesn’t solve the fundamental issue.
The “fundamental issue” is that, in order for results to be scientifically useful, they need to be linked back to scientific reasoning, and neither p-values nor preregistration strengthen the link between results and reasoning. Consequently, reducing p-hacking by increasing preregistration doesn’t improve our scientific inferences. Indeed, preregistration distracts attention away from scientific reasoning by replacing a selective reporting criterion (p-hacking) with a superficial evaluation heuristic (preregistered vs. not preregistered).

Preregistration advocates would argue that preregistration is not supposed to strengthen the link between results and reasoning. It’s merely intended to distinguish confirmatory tests from exploratory tests. But they also concede that confirmatory tests are not necessarily better than exploratory tests because researchers can preregister low quality hypotheses, methods, and analyses. However, if an exploratory test can be better than a confirmatory test, then it’s unclear why we need the confirmatory-exploratory distinction in the first place. Surely, the most rigorous scientific evaluation should consider each test on its own merits, regardless of whether it’s been preregistered? Here’s a quote from my article with Chris:
Ultimately, the assessment of any claim comes from an attempt to understand and criticize the contents of the scientific arguments that have been presented. Simplistic heuristics, such as ‘QRPs tend to be problematic’ or ‘exploratory results tend to be more tentative’ represent a form of methodologism (Chamberlain, 2000; Gao, 2014) that should not contribute to any such evaluation, since only the contents of the specific arguments themselves matter (Rubin & Donkin, 2022, p. 16).
But…bias! We need to reduce biased reporting, and p-hacking represents biased reporting? Not necessarily! P-hacking represents the selective reporting of significant results, and if all significant results are reported, including those that disconfirm hypotheses, then p-hacking will not present a biased picture of the evidence for and against those hypotheses.
Of course, nefarious researchers may also attempt to hide significant disconfirmatory results, and it may be argued that preregistration makes it more difficult for them to do so. But this argument overlooks the scientific reasoning that led to the associated tests being preregistered in the first place! If there are good theoretical, methodological, and/or analytical reasons to preregister a test, then those reasons should remain relevant and accessible to researchers and their reviewers and readers in the absence of preregistration, and the omission of the test from a research report should raise red flags regardless of whether or not it’s been preregistered.
“But,” say preregistration advocates, “researchers are able to come up with good post hoc reasons to support multiple different theoretical, methodological, and/or analytical approaches.” True! However, as Chris points out, preregistering one of these equally reasonable approaches doesn’t imbue it with any special evidential advantage other the others. It’s more appropriate to consider all reasonable approaches (e.g., via robustness or multiverse analyses) than to focus on a single approach that happens to have been preregistered. Indeed, preregistration may increase bias in this respect by awarding unwarranted evidential value to planned tests relative to equally reasonable and valid unplanned tests.
Stephan Lewandowsky
Here’s the abstract for Stephan’s presentation:

And his presentation is here. (Be prepared for the fire alarm! 🔥🧑🚒)
Like Chris, Stephan argues that:
Temporal order does not matter. What matters is the independence of the prediction from the data.

Stephan also agrees with Chris about the arbitrariness of preregistration:
Why does a preregistered analysis plan deserve special status?
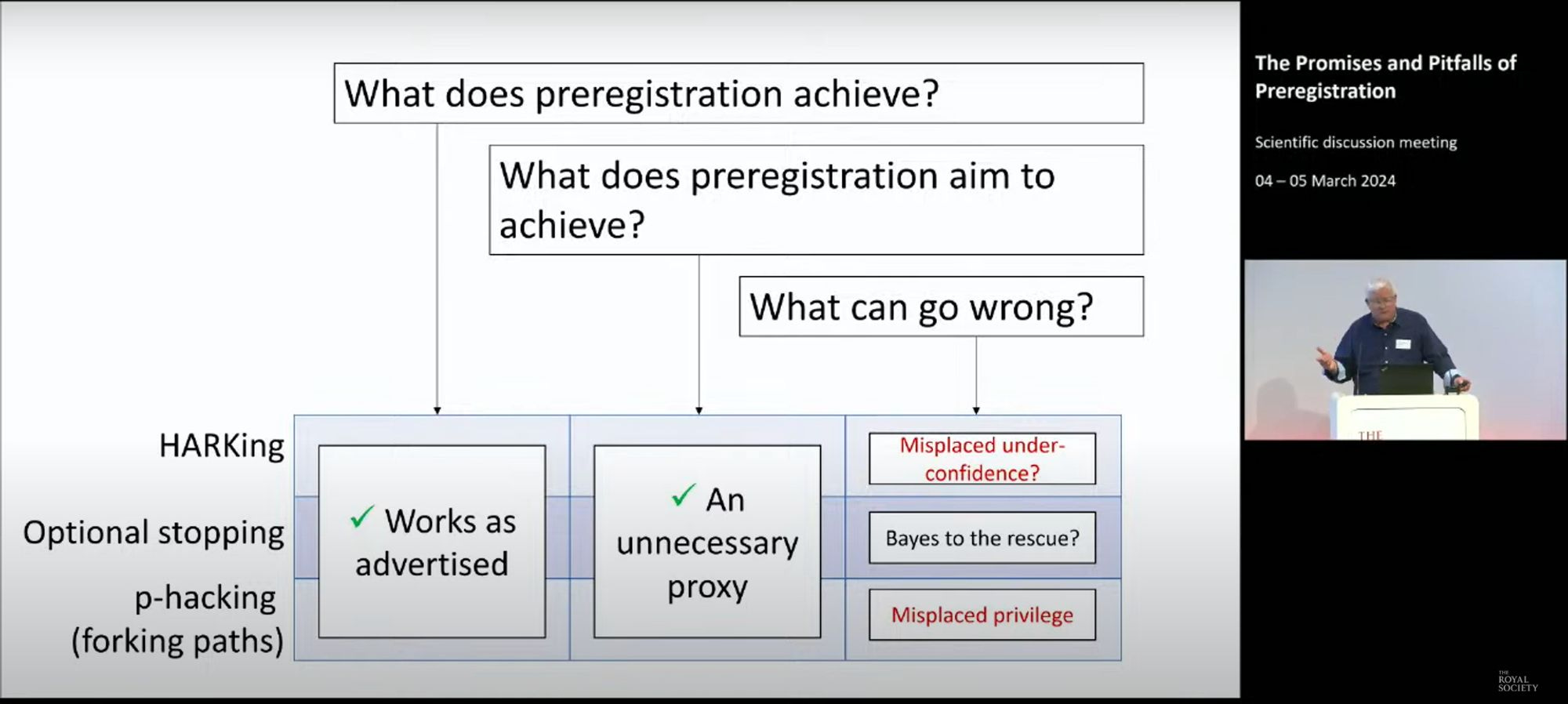
He also points out a potential cost of preregistration: It can focus our attention on one particular analytical path when other paths are equally justifiable (a sort of analytical “myopia”).

Stephan concludes that preregistration “works as advertised” but that it does so as “an unnecessary proxy” that comes with certain costs, including “misplaced underconfidence” about HARKed hypotheses and “misplaced privileging” of the particular forking path(s) that happen to have been arbitrarily preregistered.
Relevant Articles
It’s great to see these issues being discussed by such eloquent speakers. But if you’re more into the written word, please see the following relevant publications.
Oberauer, K., & Lewandowsky, S. (2019). Addressing the theory crisis in psychology. Psychonomic Bulletin & Review, 26(5), 1596-1618. https://doi.org/10.3758/s13423-019-01645-2
Rubin, M., & Donkin, C. (2022). Exploratory hypothesis tests can be more compelling than confirmatory hypothesis tests. Philosophical Psychology. https://doi.org/10.1080/09515089.2022.2113771
Szollosi, A., & Donkin, C. (2021). Arrested theory development: The misguided distinction between exploratory and confirmatory research. Perspectives on Psychological Science, 16(4), 717-724. https://doi.org/10.1177/1745691620966796
Szollosi, A., Kellen, D., Navarro, D. J., Shiffrin, R., van Rooij, I., Van Zandt, T., & Donkin, C. (2020). Is preregistration worthwhile? Trends in Cognitive Science, 24(2), 94-95. https://doi.org/10.1016/j.tics.2019.11.009
Other “Promises and Pitfalls of Preregistration” Blog Posts
This post summarises two presentations that focused on the “pitfalls” of preregistration. If you’re looking for broader summarises of the conference that focused a bit more on the “promises” of preregistration, then I can recommend the following:
Bastian, H. (2024, March 22). Study preregistration and avoiding the methods fetish/demonization trap. Absolutely Maybe. https://absolutelymaybe.plos.org/2024/03/22/study-preregistration-and-avoiding-the-methods-fetish-demonization-trap/
Syed, M. (2024, March 15). Preregistration: More promises than pitfalls: Or, maybe the real pitfalls are different from what we usually think. Get Syeducated.
Is it possible to "evaluate an unplanned exploratory test as being better than a planned confirmatory test"? It seems to me like they are different types of test, and hard to measures on the same scale (precisely because the extent of the unknown unknowns in the case of exploratory tests)